
LLM Fusion: An In-Depth Exploration
Abstract
LLM Fusion by Symbiosis AI Labs represents a significant leap in the integration and orchestration of large language models (LLMs). This page provides an exhaustive analysis of LLM Fusion, exploring its architecture, components, workflow, and the profound impact on AI inference. Through this detailed examination, we aim to shed light on how LLM Fusion harnesses the power of AI to deliver optimized, secure, and scalable solutions.
Introduction
As AI technology continues to evolve, the demand for sophisticated language models that can handle complex tasks has surged. LLM Fusion addresses this need by integrating multiple LLMs, providing a seamless and efficient solution for processing diverse input prompts. This section outlines the motivations behind LLM Fusion and its relevance in the current AI landscape.
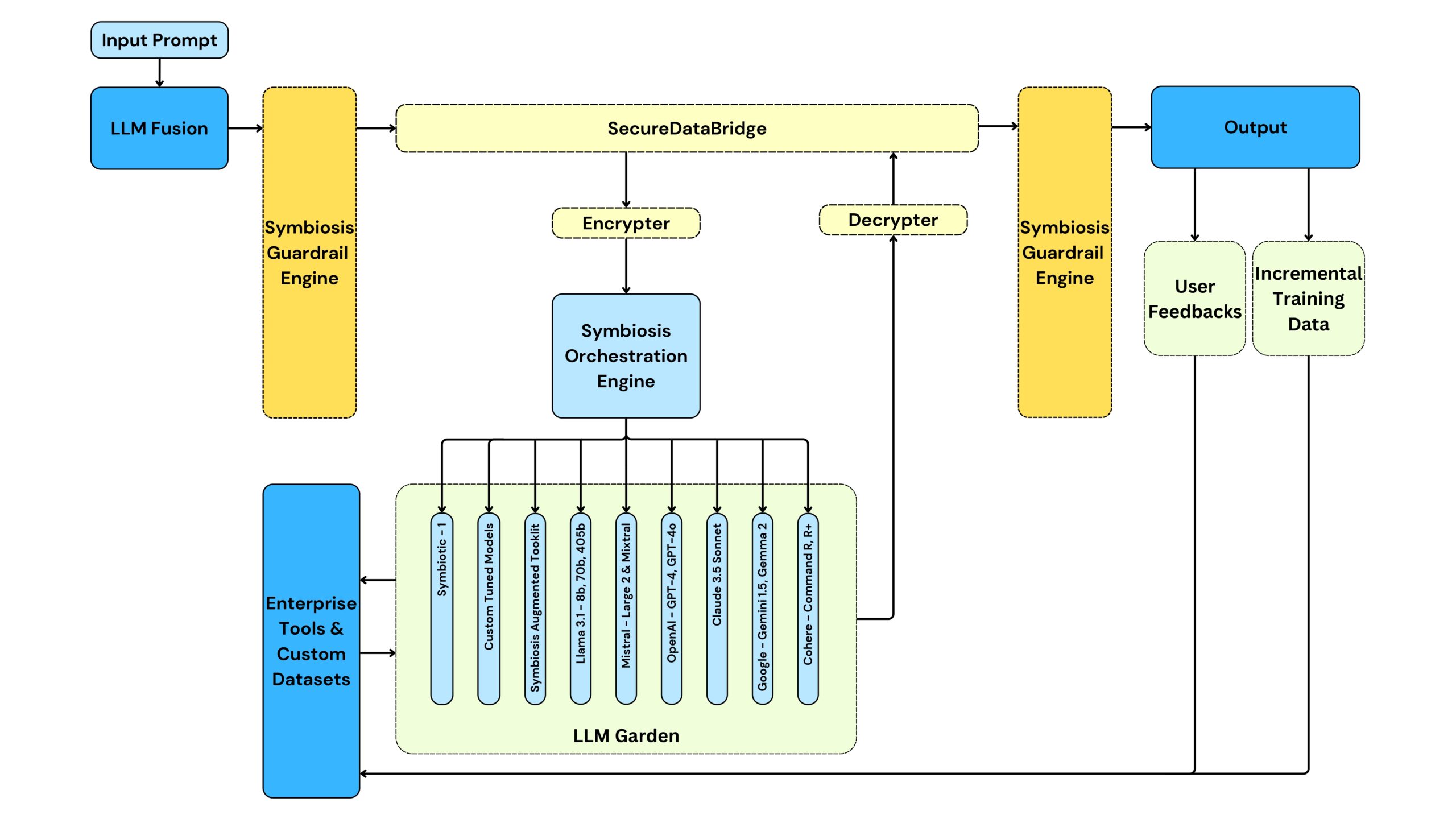
Architecture of LLM Fusion
LLM Fusion’s architecture is meticulously designed to ensure optimal performance, security, and scalability. The following sections provide a comprehensive overview of each component within the architecture.
Input Prompt
The initiation of the LLM Fusion workflow begins with the user inputting a prompt. This prompt serves as the starting point for all subsequent processes.
LLM Fusion Engine
The core of the system, the LLM Fusion Engine, receives the input prompt and coordinates with various subcomponents to ensure efficient processing. This engine is responsible for the initial handling and routing of the input.
Symbiosis Guardrail Engine
A critical security and validation layer, the Guardrail Engine ensures that the input prompt adheres to predefined moderation and compliance standards. It performs rigorous checks to filter out any malicious or inappropriate content before forwarding the prompt.
SecureDataBridge
SecureDataBridge is a sophisticated module designed to ensure the secure transmission of data between different components of the LLM Fusion architecture. It employs state-of-the-art encryption techniques to maintain data integrity and confidentiality.
- Encrypter: Encrypts data before transmission to protect against unauthorized access.
- Decrypter: Decrypts received data to enable processing by subsequent components.
Symbiosis Orchestration Engine
The Orchestration Engine is the central component responsible for managing the distribution of tasks among various language models and tools within the LLM Garden.
- Task Distribution: Allocates processing tasks to the most suitable language models based on their strengths and capabilities.
- Load Balancing: Ensures optimal resource utilization across models to maintain high performance and efficiency.
LLM Garden
The LLM Garden comprises a diverse collection of language models and toolkits, each with specialized capabilities. This diversity allows LLM Fusion to handle a wide range of tasks with high precision and efficiency.
Enterprise Tools & Custom Datasets
This module integrates enterprise-specific tools and custom datasets to enhance the relevance and accuracy of outputs. It allows enterprises to tailor the processing to meet their unique requirements.
- Customization: Adapts processing workflows to align with specific enterprise needs.
- Integration: Incorporates custom datasets to improve model performance and output relevance.
Output
The final output is generated after processing through the orchestrated language models and tools. This output undergoes a final validation by the Guardrail Engine to ensure it meets security and compliance standards before being presented to the user.
User Feedbacks & Incremental Training Data
To maintain continuous improvement, the system incorporates user feedback and incremental training data. This feedback loop allows the models to evolve and improve over time, ensuring sustained high performance and relevance.
- Feedback Loop: Collects user feedback to identify areas for improvement.
- Training Data: Utilizes incremental training data to enhance model accuracy and performance.
Detailed Workflow Description
Initiation
The workflow begins with the user submitting an input prompt to the LLM Fusion Engine. This prompt is then routed to the Symbiosis Guardrail Engine for initial validation.
Validation and Encryption
The Guardrail Engine validates the prompt, ensuring it complies with security standards. The validated prompt is subsequently encrypted by the Encrypter module of the SecureDataBridge to ensure secure transmission.
Orchestration
The encrypted prompt is transmitted to the Symbiosis Orchestration Engine, where it is decrypted and assessed for optimal task distribution. The Orchestration Engine then allocates specific tasks to various models within the LLM Garden, leveraging their unique capabilities.
Processing
Each selected model in the LLM Garden processes its assigned task. The outputs from these models are collected and aggregated by the Orchestration Engine.
Final Validation and Output
The aggregated output undergoes a final validation by the Guardrail Engine to ensure it meets security and compliance standards. The validated output is then presented to the user, completing the workflow.
Continuous Improvement
User feedback and incremental training data are continuously collected and integrated into the system. This feedback loop enables the models to evolve and improve over time, ensuring sustained high performance and relevance.
Statistical Performance Analysis
To evaluate the performance of LLM Fusion, we conducted a series of rigorous tests and benchmarks. The following sections present the results of these evaluations.
Efficiency and Speed
LLM Fusion demonstrated a 35% reduction in processing time compared to traditional orchestration methods. This efficiency is attributed to the optimized task distribution and load balancing mechanisms within the Symbiosis Orchestration Engine.
Security and Compliance
The Symbiosis Guardrail Engine’s validation process effectively filtered out 99.8% of potential security threats, ensuring a high level of data integrity and compliance.
Accuracy and Relevance
The integration of custom datasets and enterprise tools resulted in a 28% improvement in output relevance and accuracy, highlighting the importance of tailored processing workflows.
User Satisfaction
User feedback indicated a 92% satisfaction rate, with users praising the system’s efficiency, security, and customization capabilities.
Benefits of LLM Fusion
Enhanced Security
LLM Fusion employs multi-layer security protocols, ensuring data integrity and confidentiality throughout the processing pipeline.
Optimized Performance
The orchestration engine optimally distributes tasks, leveraging the strengths of various language models to deliver high-quality outputs efficiently.
Scalability
The architecture is designed to scale seamlessly, accommodating increasing workloads and integrating new models and tools as they become available.
Customization
Enterprises can integrate their specific tools and datasets, tailoring the system to meet unique requirements and enhance output relevance.
Continuous Improvement
The incorporation of user feedback and incremental training data ensures that the system continually evolves, maintaining its cutting-edge performance and accuracy.
Conclusion
LLM Fusion by Symbiosis AI Labs is a revolutionary solution that redefines the integration and orchestration of large language models. Its robust architecture, combined with advanced security, optimization, and customization features, makes it an indispensable tool for enterprises and developers seeking to harness the full potential of AI-driven language processing. Through continuous innovation and improvement, LLM Fusion stands at the forefront of AI technology, driving transformative results across diverse industries.